Generative AI and LLMs in Clinical and Laboratory Medicine

Why Do We Need a New AI in Medicine?
Limitations of classical statistical models
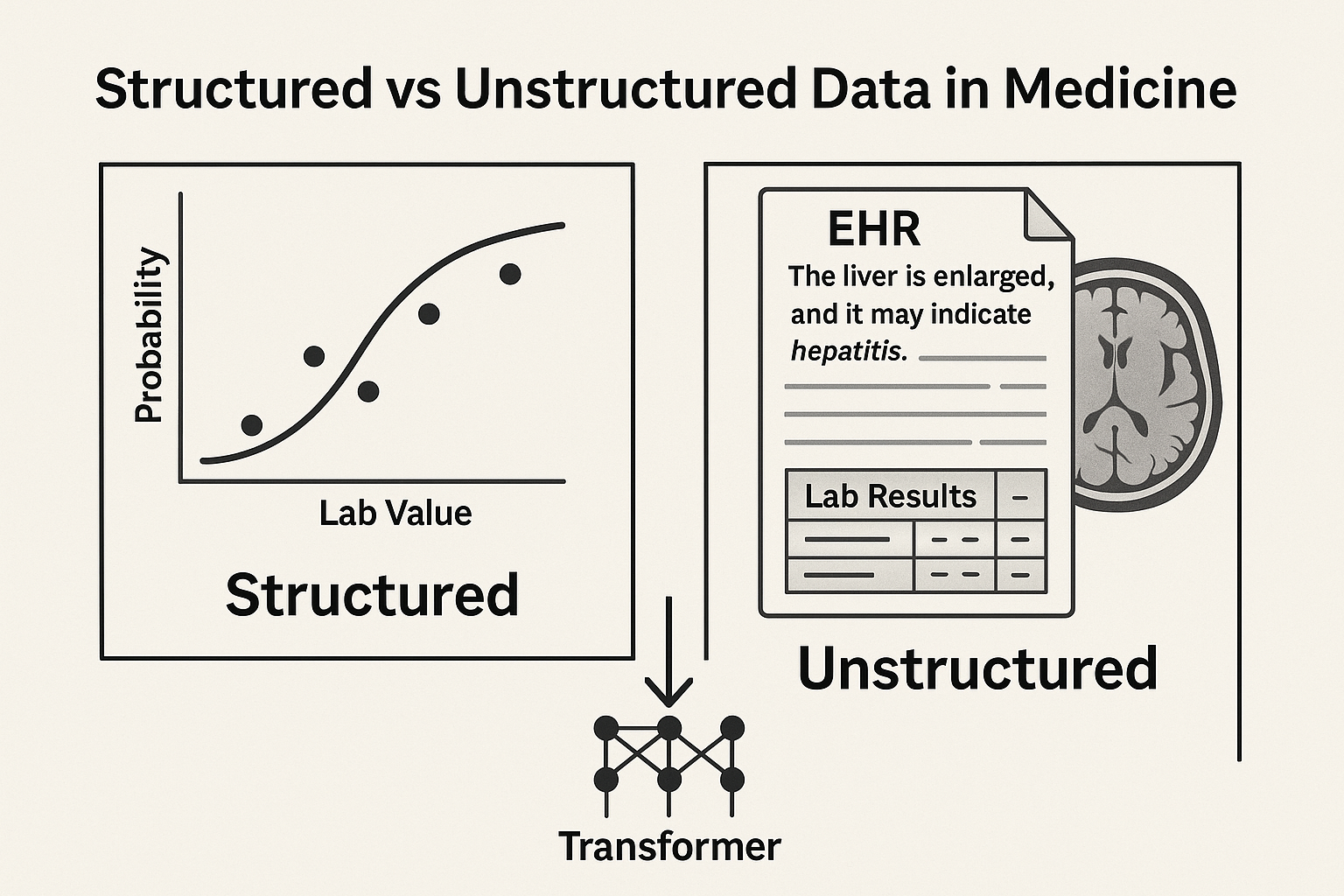
What Can Traditional AI Do?
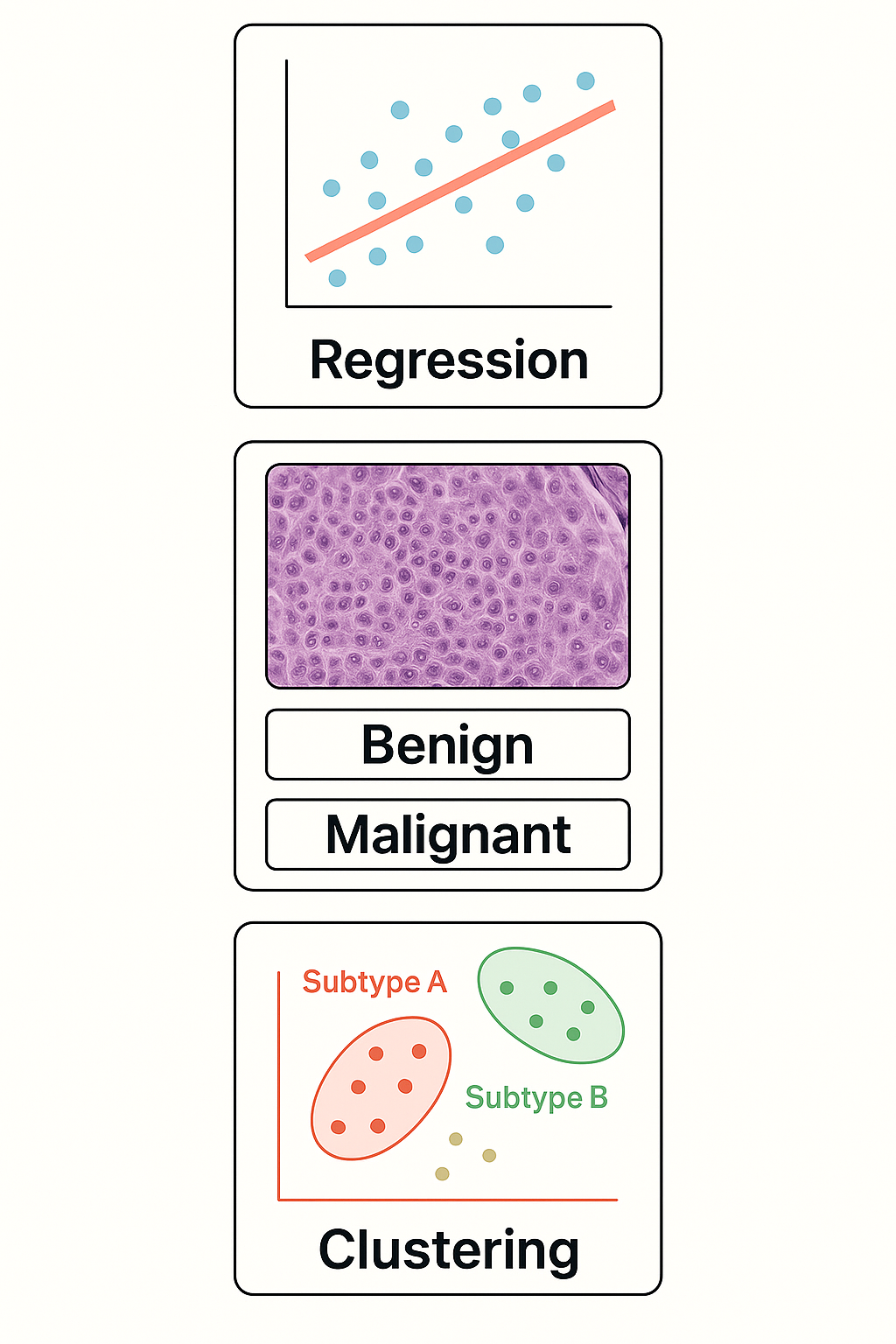
Core Tasks in Statistical Learning
- 📈 Regression: Predict a number from input data
- Example: Predict blood glucose from age + BMI
- Example: Predict blood glucose from age + BMI
- 🧪 Classification: Assign a label to input data
- Example: “Is this biopsy malignant or benign?”
- Example: “Is this biopsy malignant or benign?”
- 🔍 Clustering: Find hidden groups in unlabeled data
- Example: Identify subtypes of patients with similar gene expression
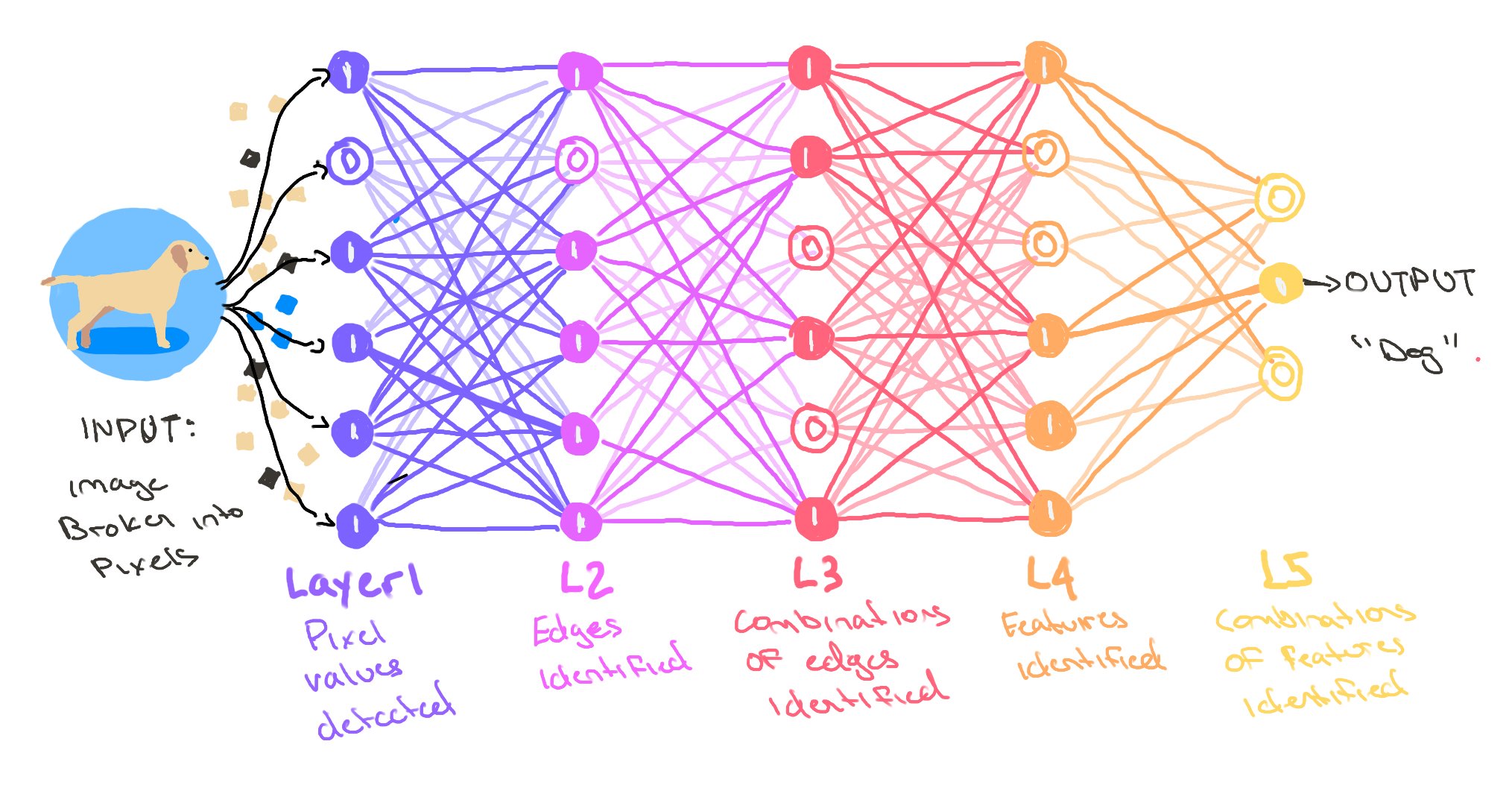
What Is a Neural Network?
From neurons to layers to learning
- 🔢 Neural networks are made of units (“neurons”) connected in layers
- 🧠 Each neuron takes input → does a small math operation → passes output forward
- 📚 By adjusting weights during training, the network learns patterns
- 🧬 This structure lets it capture non-linear relationships (vs classical regression)
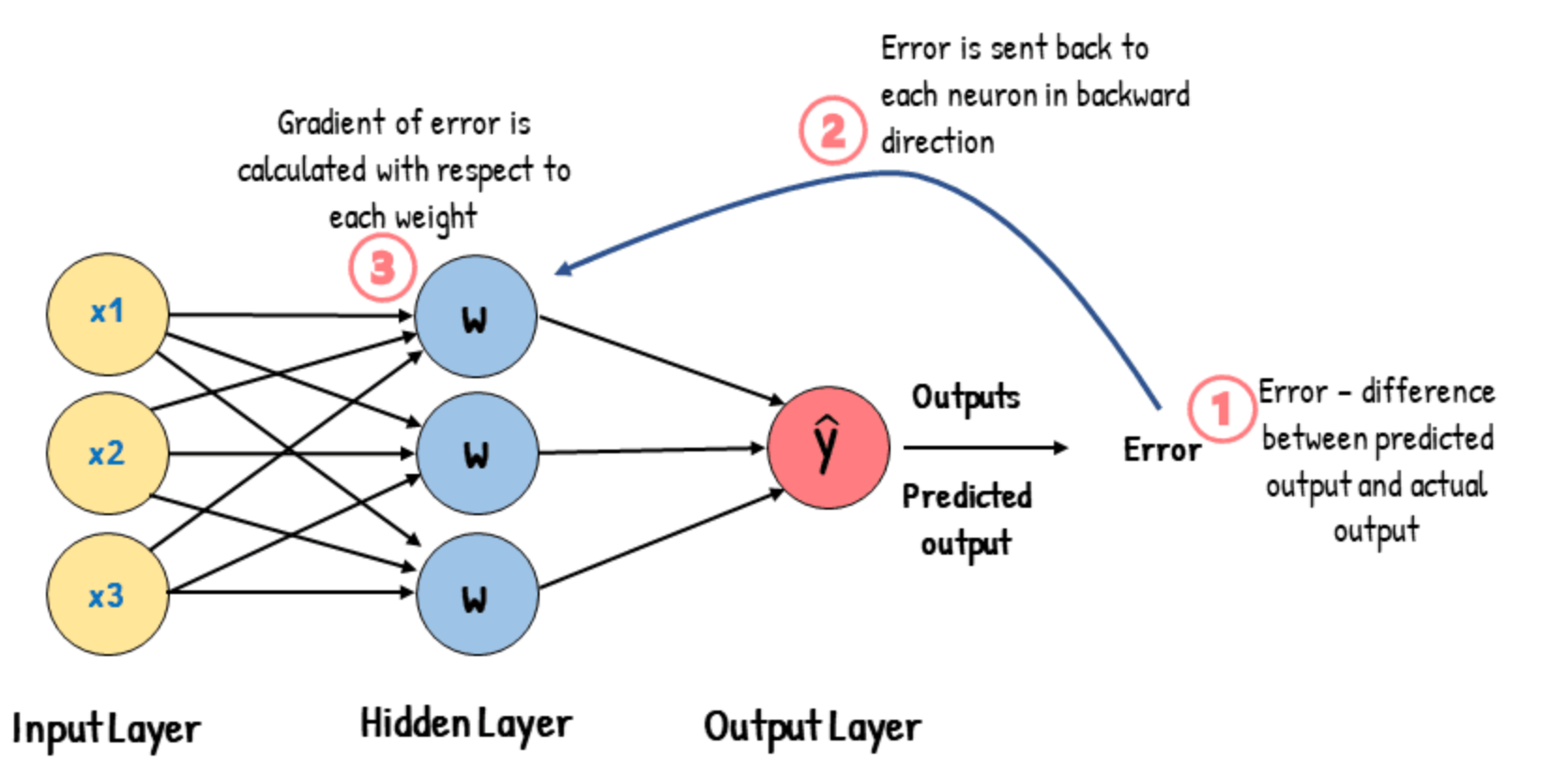
How Do Neural Networks Learn?
The role of loss and backpropagation
- 🧪 During training, the network makes a prediction
- 📉 A loss function compares the prediction to the true label
- 🔁 Backpropagation adjusts the weights to reduce error
- 🔄 This is repeated over many examples → the model learns patterns
Inside the Transformer
Self-Attention and Positional Encoding
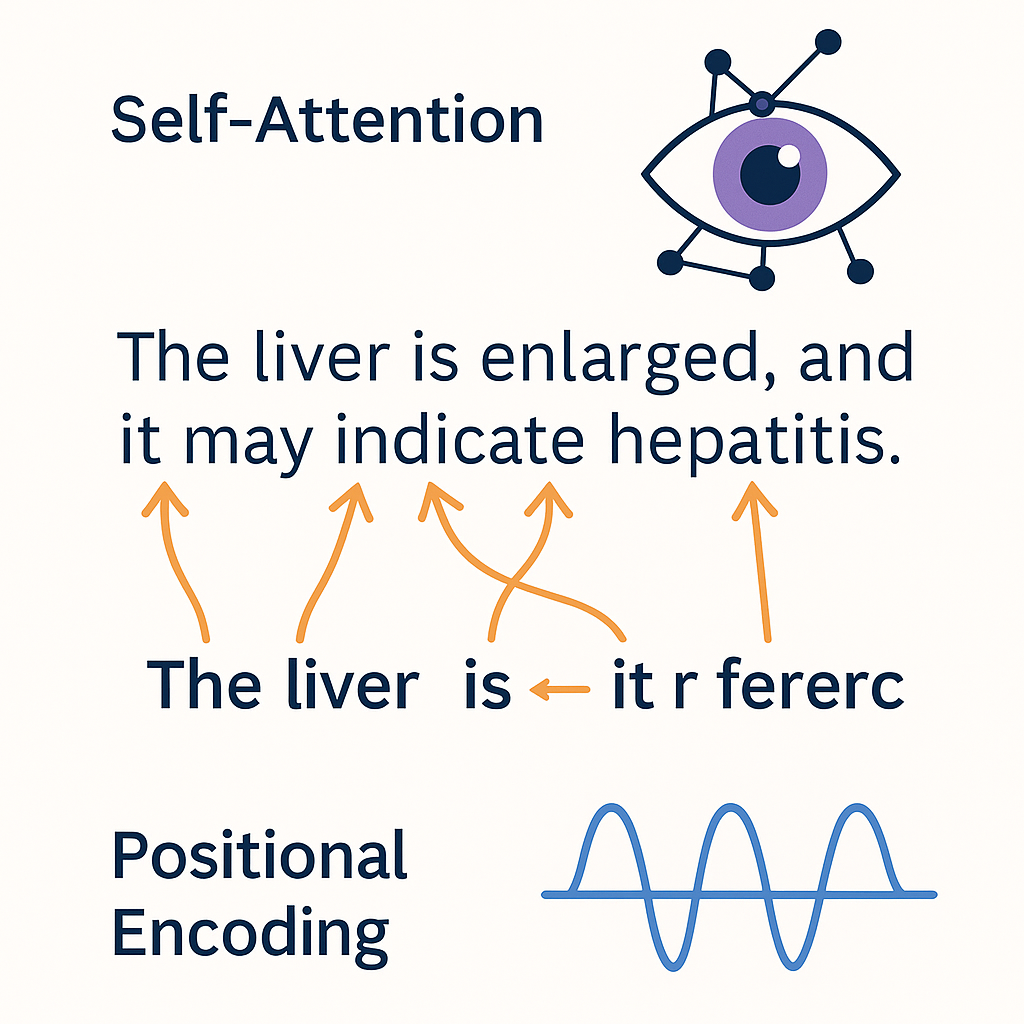
- 👁️ Self-Attention: lets the model look at all words in a sentence at once
- Each word can “attend” to other words — capturing context and meaning
- Example: in “The liver is enlarged, and it may indicate…”, what does “it” refer to?
- Each word can “attend” to other words — capturing context and meaning
- 🧭 Positional Encoding: adds order to the sequence
- Transformers process input in parallel, so positions must be encoded explicitly
- Transformers process input in parallel, so positions must be encoded explicitly
- 🔍 These are what let LLMs handle long-range dependencies in language
- 🧠 Basis for ChatGPT, BERT, and every modern LLM
What is Positional Encoding?
How Transformers know the order of words
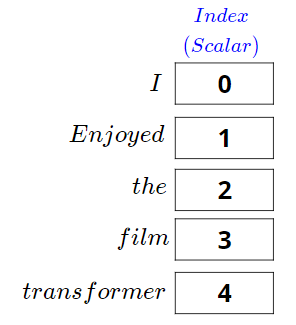
- 🧠 Transformers see all words together — but they need to know their order
- 🧭 Positional Encoding adds information about position to each word
- 🔢 Two ways to encode position:
- Add fixed patterns (e.g., sine and cosine functions)
- Or learn position embeddings during training
- 🧩 Without positional encoding:
- The model would treat sentences like unordered bags of words!
Embeddings in Transformers
First step before Attention
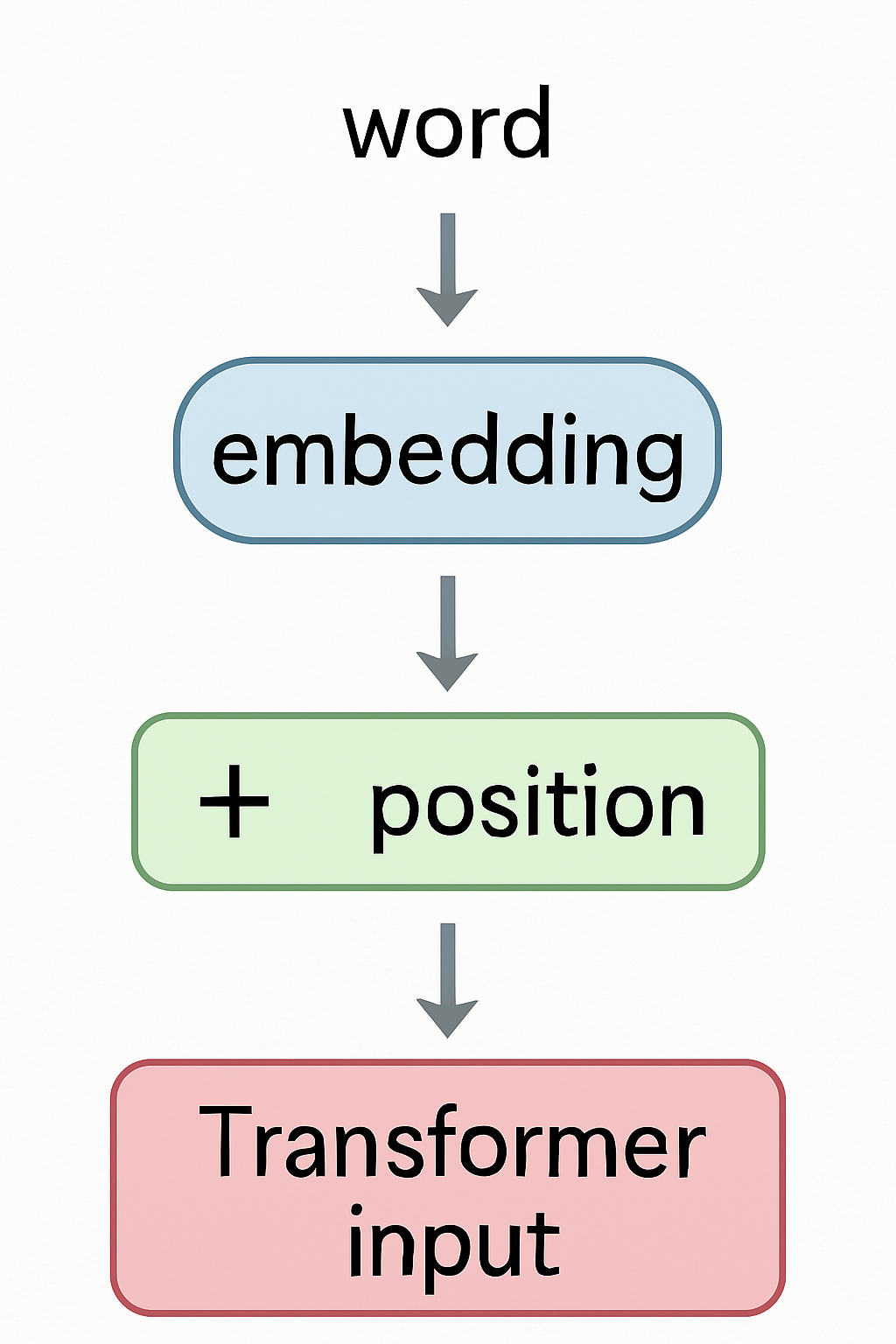
- 🏗️ Each input word is mapped to its embedding vector
- ➡️ Then positional encoding is added
- ⚡ The combined vector enters the Transformer layers
- 🎯 Embeddings are fine-tuned during training
What is Fine-tuning?
Specializing the model for a specific task
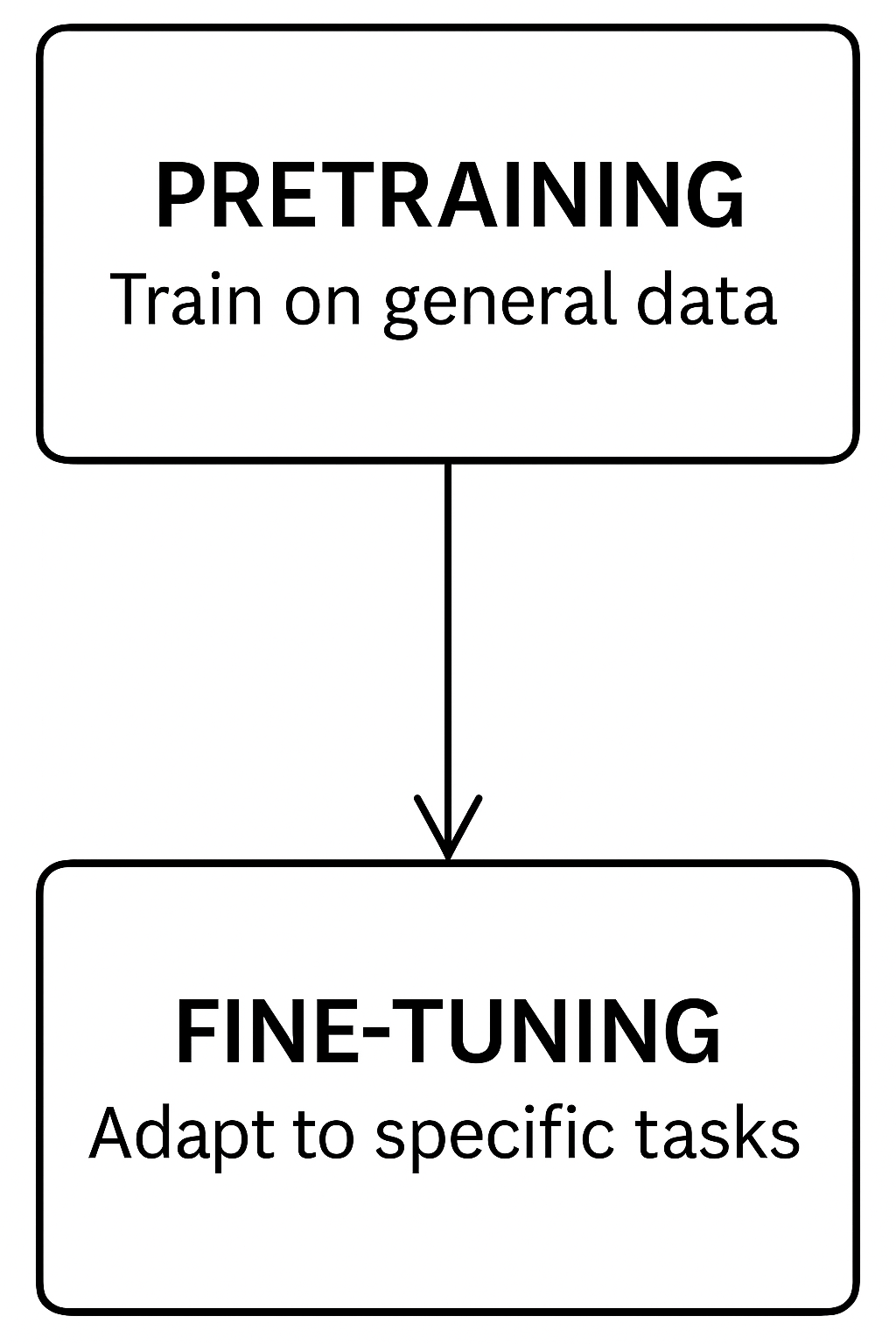
- 🔧 Fine-tuning = additional training on specific datasets
- 🧪 Goal: adapt the model to medical, clinical, or lab tasks
- 🏥 Examples:
- Predict disease from symptoms
- Summarize lab results
- Generate medical reports
- 🎯 Result: a specialized model focused on a domain
Cost-Benefit Analysis of LLMs in Clinical Settings
ROI considerations for medical implementations
- 💰 Cost factors:
- API costs: $0.50-$20 per 1,000 clinical notes (model dependent)
- Staff time saved: 20-40% reduction in documentation time
- Training & implementation: 40-80 hours per department
- 📊 Real-world ROI examples:
- Hospital A: 50% reduction in discharge summary time (saving 15 min/patient)
- Clinic B: 30% increase in note completeness and quality
- Lab C: 70% faster protocol drafting for new tests
Note
ROI is typically reached within 3-6 months when focusing on high-volume documentation tasks.
![]()